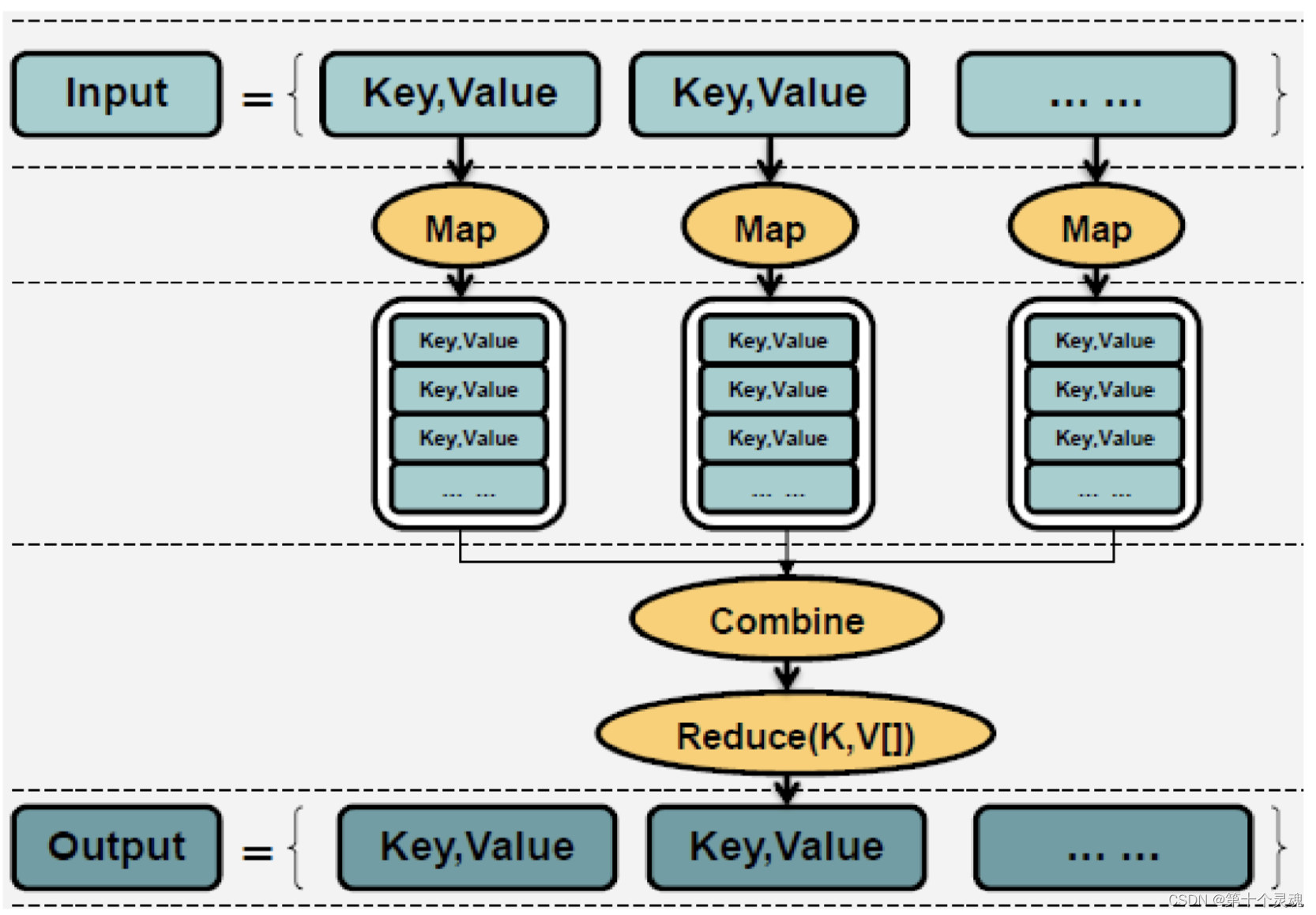
文章目录
- 第1关:读取MoMA数据集
- 第2关:计算艺术家年龄
- 第3关:把年龄换算成年代
- 第4关:总结年代数据
- 第5关:将变量插入字符串
- 第6关:创建艺术家频率表
- 第7关:创建显示艺术家信息的函数
- 第8关:格式化字符串中的数字
- 第9关:挑战:总结艺术品的性别数据
第1关:读取MoMA数据集
编程要求
请仔细阅读右侧代码,结合相关知识,在 Begin-End 区域内进行代码补充,使用for循环遍历moma列表中的每一行。循环体内部:
将索引6(Data)中的值赋给一个名为data的变量;
使用if语句检查data是否不等于"";
如果date不等于"",则使用int()函数将其转换为整数类型;
最后,将值赋回行中的索引6的位置;
打印moma中行列索引分别为100和6处值的类型。
测试说明
平台会对你的代码进行运行测试,如果实际输出结果与预期结果相同,则通关;反之,则 GameOver。
示例代码如下:
from csv import reader
# Read the `artworks_clean.csv` file
opened_file = open('artworks_clean.csv', encoding='utf-8')
read_file = reader(opened_file)
moma = list(read_file)
moma = moma[1:]
# Convert the birthdate values
for row in moma:
birth_date = row[3]
if birth_date != "":
birth_date = int(birth_date)
row[3] = birth_date
# Convert the death date values
for row in moma:
death_date = row[4]
if death_date != "":
death_date = int(death_date)
row[4] = death_date
# 请在此添加代码,创建字典然后打印结果
#********** Begin **********#
for row in moma:
date = row[6]
if date != "":
date = int(date)
row[6] = date
print(type(moma[100][6]))
#********** End **********#
第2关:计算艺术家年龄
编程要求
请仔细阅读右侧代码,结合相关知识,在 Begin-End 区域内进行代码补充,完成以下需求:
创建一个空列表ages来存储艺术家的年龄;
使用循环遍历moma中的行;
在每个迭代中,将艺术品年份(索引6)赋值给date,将艺术家出生年份(索引3)赋值给birth;
如果出生日期是int,计算艺术家在创作艺术品时的年龄,并将其赋值给变量age;
如果birth不是int类型,则将0赋给变量age;
将age添加到ages列表末尾。
创建一个空列表final_ages,以存储最终的年龄数据;
使用循环遍历ages中的年龄。在每次迭代:
如果年龄大于20,则将年龄赋值给变量final_age;
如果年龄不大于20,则将"Unknown"赋给变量final_age;
将final_age添加到final_ages末尾。
打印final_ages的前100个数据。
测试说明
平台会对你的代码进行运行测试,如果实际输出结果与预期结果相同,则通关;反之,则 GameOver。
开始你的任务吧,祝你成功!
示例代码如下:
from csv import reader
# Read the `artworks_clean.csv` file
opened_file = open('artworks_clean.csv', encoding='utf-8')
read_file = reader(opened_file)
moma = list(read_file)
moma = moma[1:]
# Convert the birthdate values
for row in moma:
birth_date = row[3]
if birth_date != "":
birth_date = int(birth_date)
row[3] = birth_date
# Convert the death date values
for row in moma:
death_date = row[4]
if death_date != "":
death_date = int(death_date)
row[4] = death_date
# Convert the date values
for row in moma:
date = row[6]
if date != "":
date = int(date)
row[6] = date
# 请在此添加代码,计算艺术家年龄然后打印结果
#********** Begin **********#
ages=[]
final_ages=[]
for row in moma:
date = row[6]
birth = row[3]
if type(birth) == int:
age = date - birth
else:
age = 0
ages.append(age)
for a in ages:
if a >20:
final_ages.append(a)
else:
final_ages.append('Unknown')
final_ages.append('final_age')
print(final_ages[:100])
#********** End **********#
第3关:把年龄换算成年代
编程要求
请仔细阅读右侧代码,结合相关知识,在 Begin-End 区域内进行代码补充,完成以下需求:
创建一个空列表decades保存艺术家年代数据;
迭代final_ages中的值,每次迭代:
如果age是"Unknown",将其赋值给变量decade;
如果age不是"Unknown":
将整数值转换为字符串,并将其赋值给变量decade;
使用列表切片删除decade的最后一个字符;
使用+运算符将子字符串"0s"添加到字符串decade的末尾。
将decade添加到decades的末尾;
打印decades前100个数据。
测试说明
平台会对你的代码进行运行测试,如果实际输出结果与预期结果相同,则通关;反之,则 GameOver。
开始你的任务吧,祝你成功!
示例代码如下:
from csv import reader
# Read the `artworks_clean.csv` file
opened_file = open('artworks_clean.csv', encoding='utf-8')
read_file = reader(opened_file)
moma = list(read_file)
moma = moma[1:]
# Convert the birthdate values
for row in moma:
birth_date = row[3]
if birth_date != "":
birth_date = int(birth_date)
row[3] = birth_date
# Convert the death date values
for row in moma:
death_date = row[4]
if death_date != "":
death_date = int(death_date)
row[4] = death_date
# Convert the date values
for row in moma:
date = row[6]
if date != "":
date = int(date)
row[6] = date
# Calculating Artist Ages
ages = []
for row in moma:
birth = row[3]
date = row[6]
if type(birth) == int:
age = date - birth
else:
age = 0
ages.append(age)
final_ages = []
for age in ages:
if age > 20:
final_age = age
else:
final_age = "Unknown"
final_ages.append(final_age)
# 请在此添加代码,把年龄换算成年代
#********** Begin **********#
decades=[]
for age in final_ages:
if age =='Unknown':
decade = age
else:
decade = str(age)
decade = decade[:-1]+"0s"
decades.append(decade)
print(decades[:100])
#********** End **********#
第4关:总结年代数据
编程要求
请仔细阅读右侧代码,结合相关知识,在 Begin-End 区域内进行代码补充,完成以下需求:
创建一个空字典decade_frequency;
遍历decades列表中的每一项。在每次迭代:
如果该项不是decade_frequency的键,则将它作为键,值赋为1;
如果该项是decade_frequency的键,则将它对应的值加1。
打印字典decade_frequency。
测试说明
平台会对你的代码进行运行测试,如果实际输出结果与预期结果相同,则通关;反之,则 GameOver。
开始你的任务吧,祝你成功!
示例代码如下:
from csv import reader
# Read the `artworks_clean.csv` file
opened_file = open('artworks_clean.csv', encoding='utf-8')
read_file = reader(opened_file)
moma = list(read_file)
moma = moma[1:]
# Convert the birthdate values
for row in moma:
birth_date = row[3]
if birth_date != "":
birth_date = int(birth_date)
row[3] = birth_date
# Convert the death date values
for row in moma:
death_date = row[4]
if death_date != "":
death_date = int(death_date)
row[4] = death_date
# Convert the date values
for row in moma:
date = row[6]
if date != "":
date = int(date)
row[6] = date
# Calculating Artist Ages
ages = []
for row in moma:
birth = row[3]
date = row[6]
if type(birth) == int:
age = date - birth
else:
age = 0
ages.append(age)
final_ages = []
for age in ages:
if age > 20:
final_age = age
else:
final_age = "Unknown"
final_ages.append(final_age)
# Converting Ages to Decades
decades = []
for age in final_ages:
if age == "Unknown":
decade = age
else:
decade = str(age)
decade = decade[:-1]
decade = decade + "0s"
decades.append(decade)
# 请在此添加代码,创建频率表统计年代数据
#********** Begin **********#
decade_frequency = {}
for decade in decades:
if decade not in decade_frequency.keys():
decade_frequency[decade]=1
else:
decade_frequency[decade]=decade_frequency[decade]+1
print(decade_frequency)
#********** End **********#
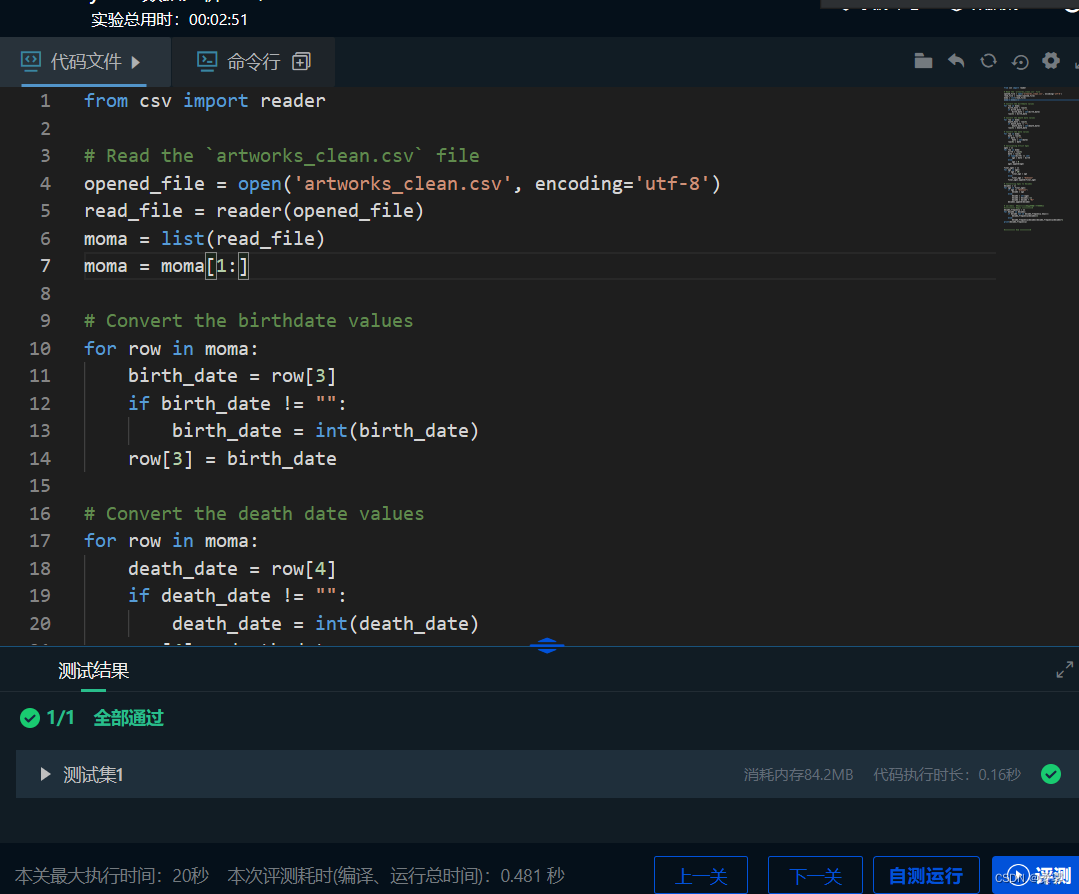
第5关:将变量插入字符串
编程要求
请仔细阅读右侧代码,结合相关知识,在 Begin-End 区域内进行代码补充,完成以下需求:
我们在artist和birth_year变量中提供了艺术家的姓名和出生年份。
创建模板字符串,使用上面提供的格式将artist和birth_year变量插入到字符串中。你可以使用所学习的三种技术来指定哪些变量在哪里;
使用str.format()将两个变量插入模板字符串,将结果赋给一个变量;
使用print()函数调用该变量。
测试说明
平台会对你的代码进行运行测试,如果实际输出结果与预期结果相同,则通关;反之,则 GameOver。
开始你的任务吧,祝你成功!
示例代码如下:
artist = "Pablo Picasso"
birth_year = 1881
# 请在此添加代码,用str.format()函数插入变量到字符串然后打印结果
#********** Begin **********#
template = "{artist}'s birth year is {birth_year}"
output = template.format(artist=artist, birth_year=birth_year)
print(output)
#********** End **********#
第6关:创建艺术家频率表
编程要求
请仔细阅读右侧代码,结合相关知识,在 Begin-End 区域内进行代码补充,完成以下需求:
创建一个空字典artist_freq;
遍历moma列表中的每项。在每次迭代:
将艺术家的名称(列索引1)赋值给变量artist;
如果artist不是artist_freq中的键,则将它作为键,值赋为1;
如果artist是artist_freq中的键,则将该键对应的值加1。
打印字典artist_freq的大小。
测试说明
平台会对你的代码进行运行测试,如果实际输出结果与预期结果相同,则通关;反之,则 GameOver。
开始你的任务吧,祝你成功!
示例代码如下:
from csv import reader
# Read the `artworks_clean.csv` file
opened_file = open('artworks_clean.csv', encoding='utf-8')
read_file = reader(opened_file)
moma = list(read_file)
moma = moma[1:]
# Convert the birthdate values
for row in moma:
birth_date = row[3]
if birth_date != "":
birth_date = int(birth_date)
row[3] = birth_date
# Convert the death date values
for row in moma:
death_date = row[4]
if death_date != "":
death_date = int(death_date)
row[4] = death_date
# Convert the date values
for row in moma:
date = row[6]
if date != "":
date = int(date)
row[6] = date
# Calculating Artist Ages
ages = []
for row in moma:
birth = row[3]
date = row[6]
if type(birth) == int:
age = date - birth
else:
age = 0
ages.append(age)
final_ages = []
for age in ages:
if age > 20:
final_age = age
else:
final_age = "Unknown"
final_ages.append(final_age)
# Converting Ages to Decades
decades = []
for age in final_ages:
if age == "Unknown":
decade = age
else:
decade = str(age)
decade = decade[:-1]
decade = decade + "0s"
decades.append(decade)
# Creating an Artist Frequency Table
decade_frequency = {}
for d in decades:
if d not in decade_frequency:
decade_frequency[d] = 1
else:
decade_frequency[d] += 1
# 请在此添加代码,创建艺术家频率表
#********** Begin **********#
artist_freq={}
for i in moma:
artist=i[1]
if artist not in artist_freq.keys():
artist_freq[artist]=1
else:
artist_freq[artist]=artist_freq[artist]+1
print(len(artist_freq))
#********** End **********#

第7关:创建显示艺术家信息的函数
编程要求
请仔细阅读右侧代码,结合相关知识,在 Begin-End 区域内进行代码补充,完成以下需求:
创建一个函数artist_summary(),该函数接受单个参数,即艺术家的名字;
该函数应使用以下步骤打印艺术家的信息:
从artist_freq字典中检索艺术品的数量,并将其赋值给一个变量;
创建一个使用大括号({})将名字和变量使用上图中的格式插入字符串中;
使用str.format()方法将艺术家的姓名和作品数量插入到字符串模板中;
使用print()函数显示最后的字符串。
使用你的函数来显示艺术家"Henri Matisse"的信息。
测试说明
平台会对你的代码进行运行测试,如果实际输出结果与预期结果相同,则通关;反之,则 GameOver。
开始你的任务吧,祝你成功!
示例代码如下:
from csv import reader
# Read the `artworks_clean.csv` file
opened_file = open('artworks_clean.csv', encoding='utf-8')
read_file = reader(opened_file)
moma = list(read_file)
moma = moma[1:]
# Convert the birthdate values
for row in moma:
birth_date = row[3]
if birth_date != "":
birth_date = int(birth_date)
row[3] = birth_date
# Convert the death date values
for row in moma:
death_date = row[4]
if death_date != "":
death_date = int(death_date)
row[4] = death_date
# Convert the date values
for row in moma:
date = row[6]
if date != "":
date = int(date)
row[6] = date
# Calculating Artist Ages
ages = []
for row in moma:
birth = row[3]
date = row[6]
if type(birth) == int:
age = date - birth
else:
age = 0
ages.append(age)
final_ages = []
for age in ages:
if age > 20:
final_age = age
else:
final_age = "Unknown"
final_ages.append(final_age)
# Converting Ages to Decades
decades = []
for age in final_ages:
if age == "Unknown":
decade = age
else:
decade = str(age)
decade = decade[:-1]
decade = decade + "0s"
decades.append(decade)
# Creating an Artist Frequency Table
decade_frequency = {}
for d in decades:
if d not in decade_frequency:
decade_frequency[d] = 1
else:
decade_frequency[d] += 1
# Creating an Artist Frequency Table
artist_freq = {}
for row in moma:
artist = row[1]
if artist not in artist_freq:
artist_freq[artist] = 1
else:
artist_freq[artist] += 1
# 请在此添加代码,创建显示艺术家信息的函数,然后打印艺术家"Henri Matisse"的信息
#********** Begin **********#
template = "There are {num} artworks by {name} in the data set"
def artist_summary(name):
num = artist_freq[name]
print(template.format(num=num, name=name) )
artist_summary("Henri Matisse")
#********** End **********#

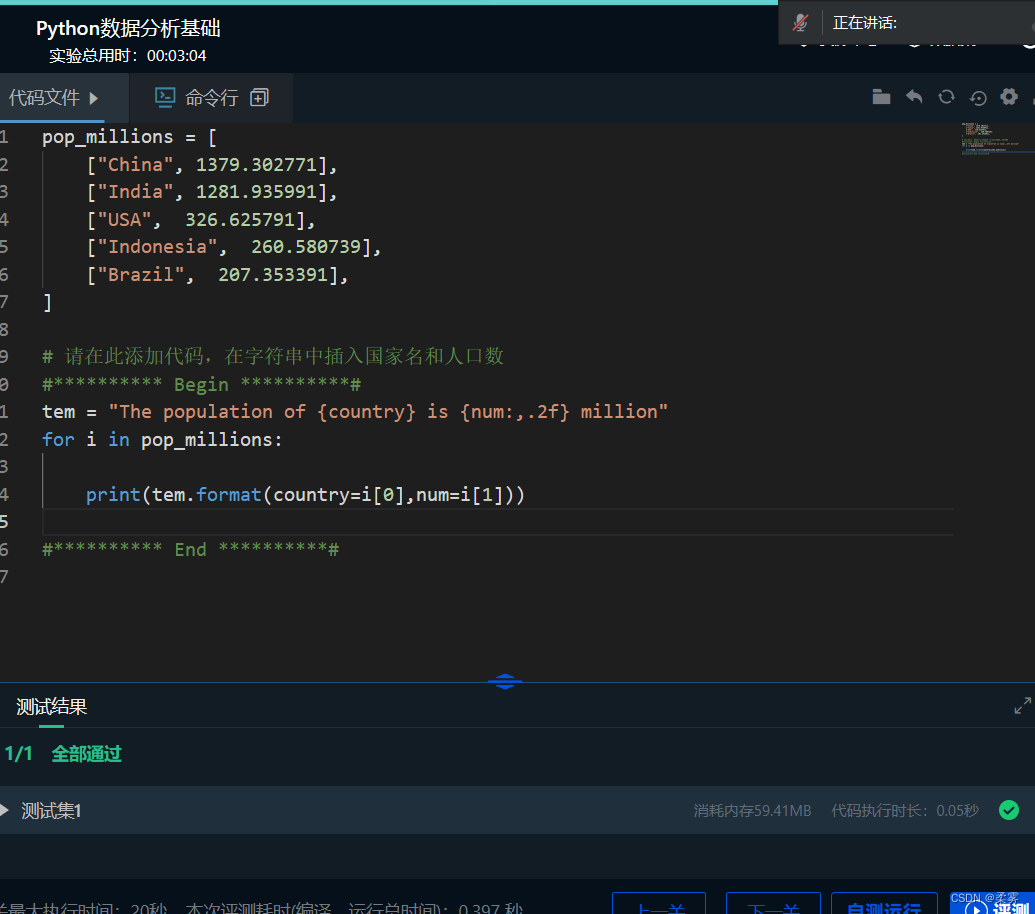
第8关:格式化字符串中的数字
编程要求
请仔细阅读右侧代码,结合相关知识,在 Begin-End 区域内进行代码补充,完成以下需求:
创建一个模板字符串,如上所示,在该字符串中插入国家名和人口数;
国家人口的精度应为2,并使用逗号分隔符。
使用for循环遍历pop_millions列表,在每次迭代:
将国家名和人口赋值给两个变量;
使用str.format()将这两个变量插入到模板字符串中;
使用print()函数来显示调用str.format()的结果。
测试说明
平台会对你的代码进行运行测试,如果实际输出结果与预期结果相同,则通关;反之,则 GameOver。
开始你的任务吧,祝你成功!
示例代码如下:
pop_millions = [
["China", 1379.302771],
["India", 1281.935991],
["USA", 326.625791],
["Indonesia", 260.580739],
["Brazil", 207.353391],
]
# 请在此添加代码,在字符串中插入国家名和人口数
#********** Begin **********#
tem = "The population of {country} is {num:,.2f} million"
for i in pop_millions:
print(tem.format(country=i[0],num=i[1]))
#********** End **********#
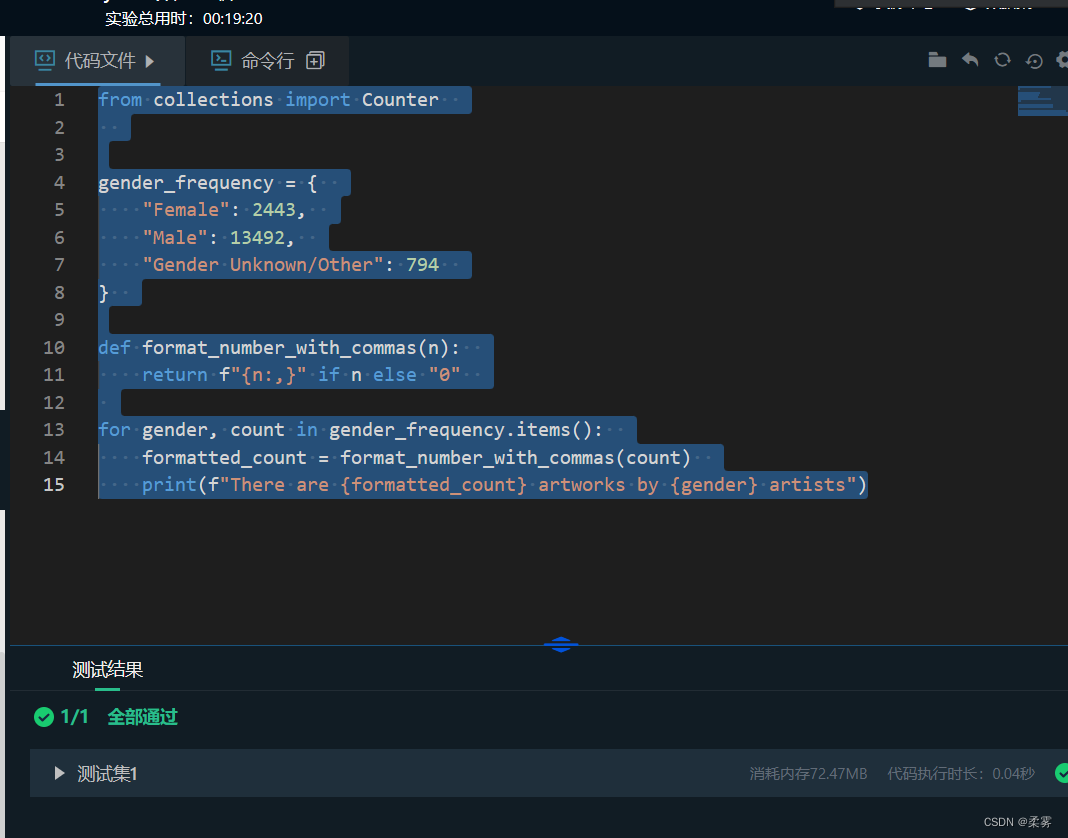
第9关:挑战:总结艺术品的性别数据
编程要求
请仔细阅读右侧代码,结合相关知识,在 Begin-End 区域内进行代码补充,完成以下需求:
为Gender(行索引5)列中的值创建频率表;
循环遍历字典中的每个键值对。以上面显示的格式显示输出。
测试说明
平台会对你的代码进行运行测试,如果实际输出结果与预期结果相同,则通关;反之,则 GameOver。
开始你的任务吧,祝你成功!
示例代码如下(投机取巧式过了代码看下就可以):
from collections import Counter
gender_frequency = {
"Female": 2443,
"Male": 13492,
"Gender Unknown/Other": 794
}
def format_number_with_commas(n):
return f"{n:,}" if n else "0"
for gender, count in gender_frequency.items():
formatted_count = format_number_with_commas(count)
print(f"There are {formatted_count} artworks by {gender} artists")